Privacy
Learn About Data Privacy and Security in VPC Deployments
VPC deployments of Predibase offer a fully separate dataplane where models are fine-tuned and deployments run.
Data Flow to VPC Deployments
There are three ways to prompt a VPC deployment in Predibase:
UI
Requests sent via the Predibase Prompt UI are sent to public serving.app.predibase.com and then sent through
our SaaS controlplane and our internal network before it reaches your dataplane, and ultimately your LLM deployment.
SDK/API
SDK or API requests to serving.app.predibase.com are routed through our SaaS controlplane and internal network before reaching your deployment.
Direct Ingress
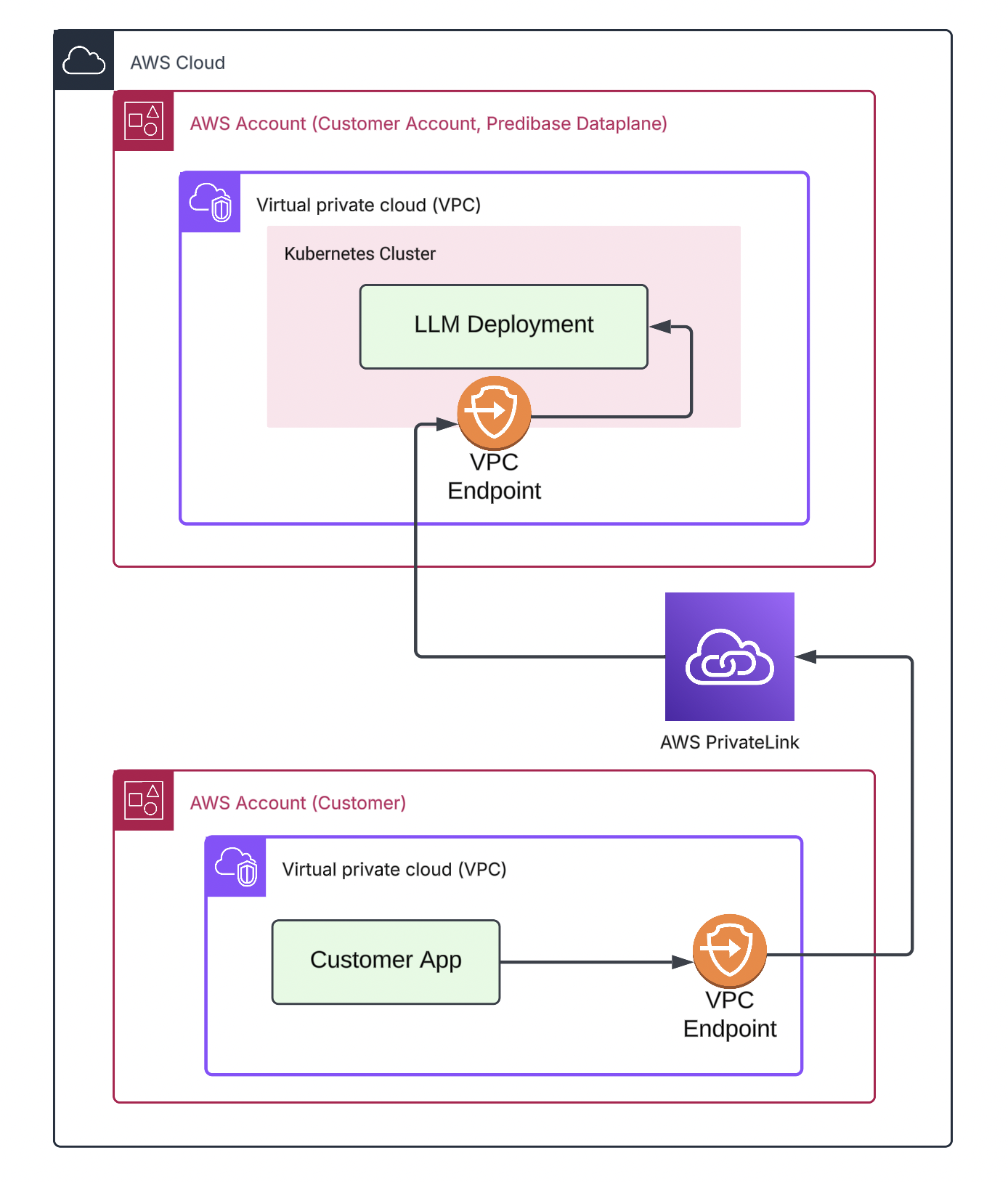
Direct ingress is Predibase feature which uses services like AWS PrivateLink to create a direct connection between your VPC and your Predibase dataplane. By routing through the cloud provider’s network, requests directly reach your deployment without external hops
Direct Ingress Setup
To enable direct ingress in your VPC:
- Contact Predibase support to enable the feature
- Create deployments with
direct_ingress=True - Use VPC endpoint instead of
serving.app.predibase.com
Your requests will then route directly from your VPC to the Predibase dataplane VPC through the cloud provider’s network, bypassing our shared SaaS controlplane and external networks.
AWS PrivateLink Network Architecture
Data Storage
Fine-tuning Datasets
With the exception of explicitly uploading a file to Predibase (under the ‘dataset connection page’), data will never be saved to disk on our servers.
For dataset connections (ex. Amazon S3):
- Credentials are stored in a secure HashiCorp Vault instance
- Credentials are read at runtime by fine-tuning workers in your VPC
- Workers use these credentials to access your datasets
For file uploads:
- Files are saved to a private cloud storage bucket within your Predibase dataplane cloud account that you manage
Request Data
By default, Predibase will never log your prompts to your LLM deployments or the responses that are generated.
You can enable prompt and response logging via a flag when creating a deployment. Some customers find this valuable for creating new datasets of prompt-response pairs for further fine-tuning models, but this feature is turned off by default for all LLM deployments.