Adapters are a powerful way to fine-tune large language models for specific tasks by introducing parameter-efficient methods that customize base models using your data without changing the original model architecture. They enable faster training, reduce the risk of overfitting, and allow for rapid experimentation.Documentation Index
Fetch the complete documentation index at: https://docs.predibase.com/llms.txt
Use this file to discover all available pages before exploring further.
How Adapters Work
Unlike traditional fine-tuning that updates all model weights, adapters introduce a small number of task-specific parameters while keeping the base model frozen. This approach offers several key benefits:- Efficiency: Training is faster and requires fewer compute resources
- Reduced Risk: By updating fewer parameters, adapters reduce the risk of catastrophic forgetting
- Flexibility: Multiple adapters can be trained and deployed on a single base model
- Storage: Adapter checkpoints are much smaller than full model checkpoints
Types of Adapters
LoRA (Low-Rank Adaptation)
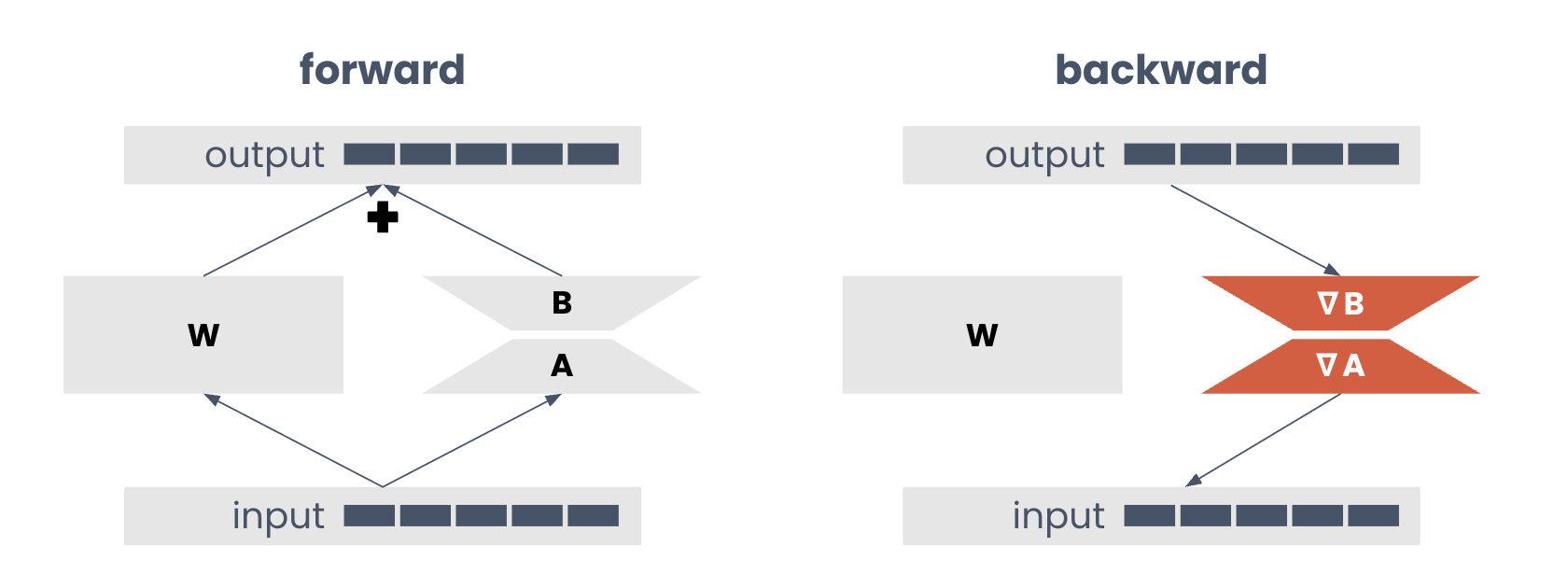
LoRA introduces trainable low-rank matrices into the model’s layers to capture task-specific adjustments. Here’s how it works:-
Architecture: LoRA inserts two matrices (A and B) into each target linear layer
within each transformer layer (attention or MLP or both):
- Matrix A projects the original weight space (hidden size) to a lower dimension (called the
rank) - Matrix B projects it back to the original size
- Matrix A projects the original weight space (hidden size) to a lower dimension (called the
-
Parameter Efficiency: LoRA typically uses only 0.1% to 1% of the
parameters in the base model - this is dependent on the
rankand the number of layers that are targeted.
Best Practices for LoRA
- Start with the default rank of 16 and adjust based on your needs:
- Increase rank for more complex tasks or when you need higher quality
- Decrease rank for simpler tasks or when you need faster training
- Target attention layers first (
q_proj,k_proj,v_proj,o_proj) and then add MLP layers (gate_proj,down_proj,up_proj).
Turbo LoRA
Turbo LoRA is a proprietary method developed by Predibase that marries the benefits of LoRA fine-tuning (for quality) with speculative decoding (for speed) to enhance inference throughput (measured in token generated per second) by up to 3.5x for single requests and up to 2x for high queries per second batched workloads depending on the type of the downstream task. Instead of just predicting one token at a time, speculative decoding allows the model to predict and verify several tokens into the future in a single decoding step, significantly accelerating the generation process, making it well-suited for tasks involving long output sequences.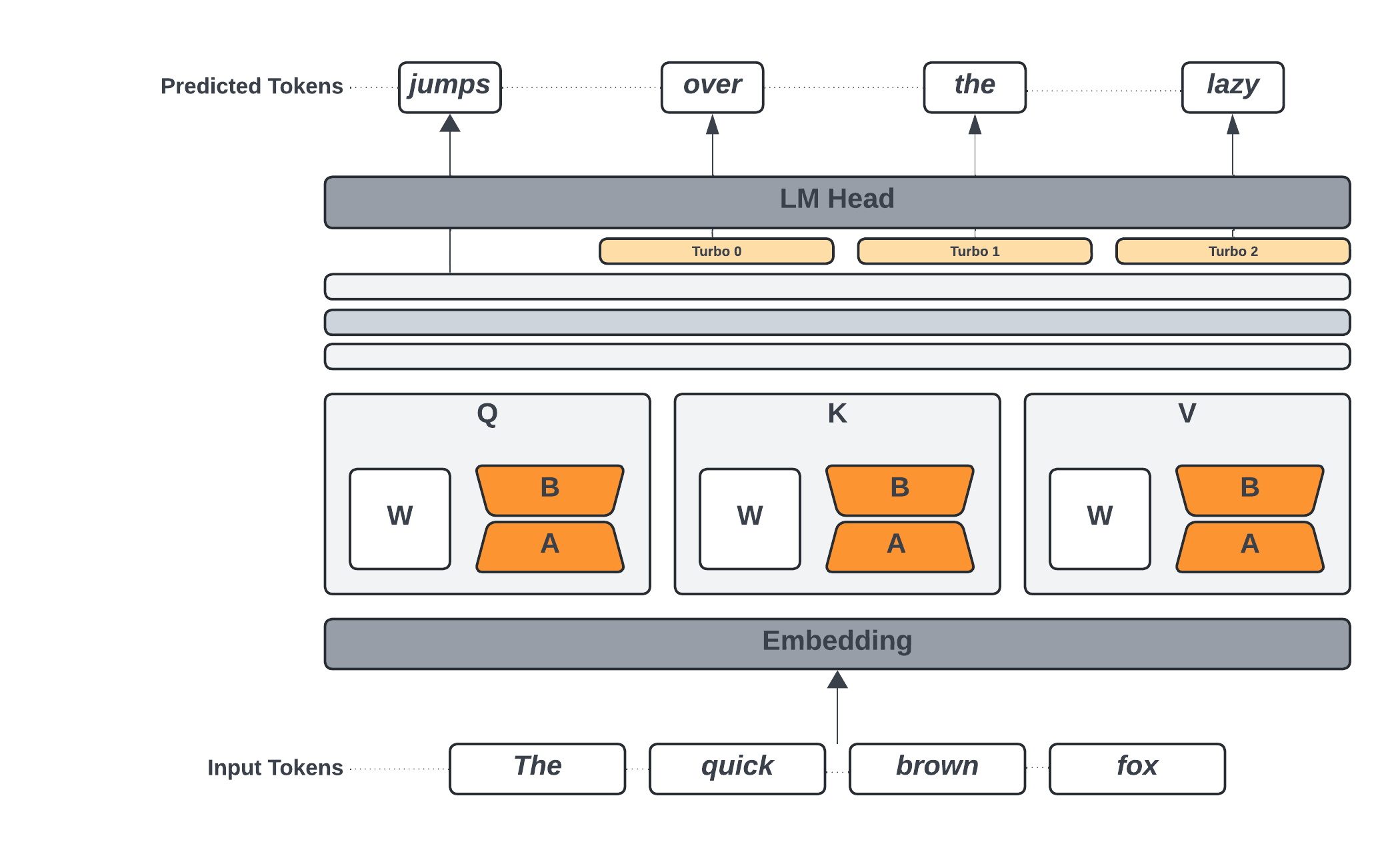
When to Use Turbo LoRA
Turbo LoRA is ideal for:- Long-form generation tasks (summarization, translation, creative writing)
- Applications requiring high throughput
- Tasks with constrained or predictable output structures like named entity recognition, structured data extraction, code generation, etc.
- Classification tasks (outputs < 10 tokens)
- Tasks requiring high output variability like chatbots, creative writing, etc.
Best Practices for Turbo LoRA
- Use at least a few thousand training examples
- Ensure training data quality is high
- Consider the trade-off between training cost (2x standard pricing) and inference speed gains
Turbo
Turbo is a specialized adapter focused purely on inference speed through speculative decoding. It’s based on the Medusa architecture but with 10x fewer parameters. It trains additional layers to predict multiple tokens in parallel, making it useful when you want to accelerate an existing base model or an already fine-tuned LoRA adapter. Note that Turbo adapters don’t train a LoRA, so none of the LoRA specific parameters like rank, alpha, dropout and target modules apply. For a hands-on example of how to train a Turbo adapter, see this Colab notebook.Key Features
- Predicts multiple tokens in parallel
- Does not change base (or fine-tuned) model outputs
- Can be applied to both base models and existing LoRA adapters
- Highly parameter efficient compared to other speculative decoding approaches
When to Use Turbo
Best for:- Accelerating existing models without changing their outputs
- Improving inference speed of already fine-tuned LoRA adapters
- Applications where consistent output quality is critical
- Training data should match the model’s original output distribution
- Works best with high-quality, diverse training data
Common Challenges and Solutions
Training Issues
-
Poor Adaptation
- Increase rank or learning rate
- Increase the number of layers targeted
- Ensure training data quality or volume
-
Slow Training
- Decrease rank
- Target fewer layers
- Use a smaller model or data with shorter context lengths
Inference Issues
-
Slow Generation
- Consider using Turbo or Turbo LoRA
- Check hardware utilization
Advanced Topics
Multi-Adapter Inference
Multiple adapters can be deployed on a single base model, enabling:- A/B testing different adapters
- Task composition
- Dynamic adapter switching to maximize GPU utilization
Adapter Composition
Adapters can be combined in various ways:- Sequential application (e.g., Turbo on top of LoRA)
- Parallel merging of multiple LoRA adapters
- Weighted combinations for task blending
Next Steps
- Explore hyperparameter tuning
- Learn about adapter deployment
- Try continued training with adapters