Reinforcement fine-tuning represents a powerful approach to optimizing language models without requiring extensive labeled data. This guide explores how reinforcement learning, particularly Group Relative Policy Optimization (GRPO), can enhance model performance.Documentation Index
Fetch the complete documentation index at: https://docs.predibase.com/llms.txt
Use this file to discover all available pages before exploring further.
Why Reinforcement Fine-tuning?
Traditional supervised fine-tuning methods have limitations:- Require high-quality labeled data
- May not directly optimize for desired behaviors
- Can be expensive and time-consuming
- Limited ability to handle complex objectives
- Using programmable reward functions
- Optimizing directly for desired outcomes
- Learning from trial and error
- Developing generalized strategies
How GRPO Works
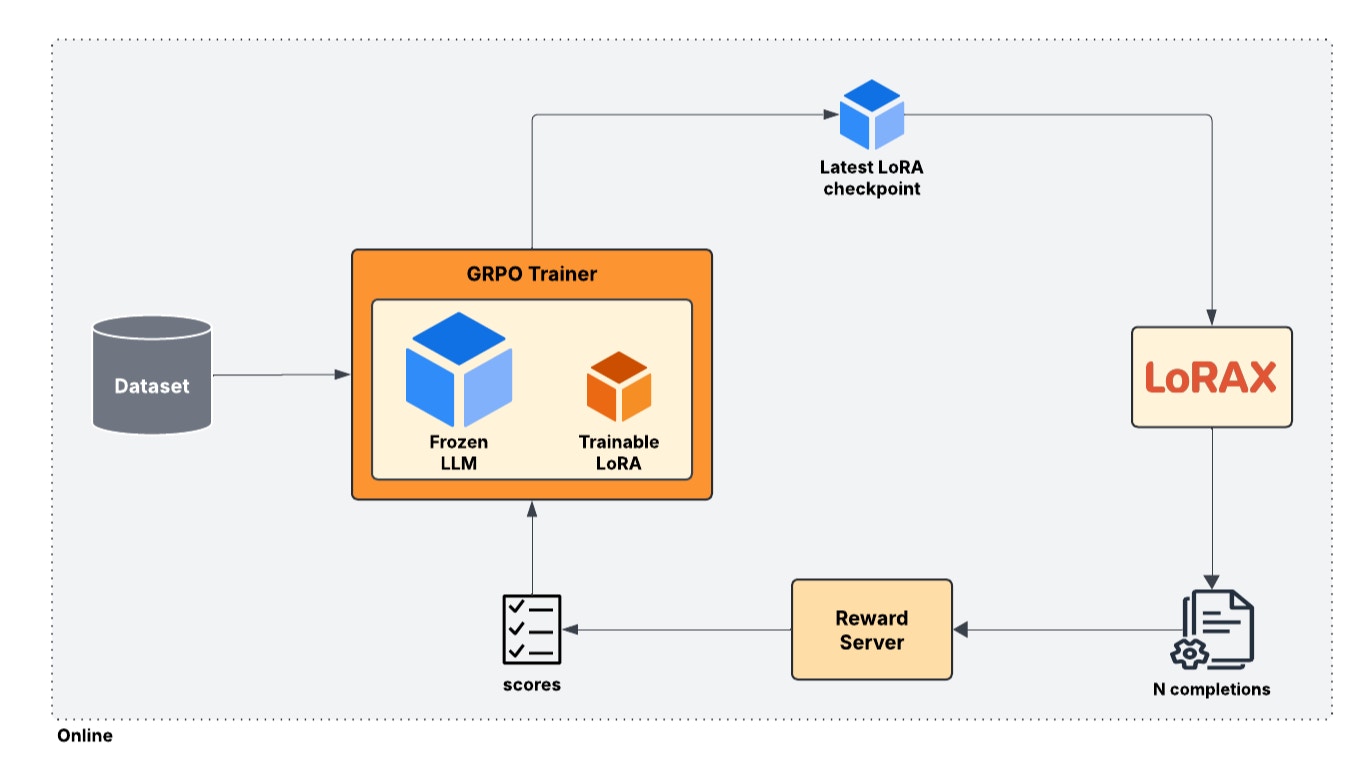
1. Dual Model Architecture
The approach uses two models:- Frozen Reference Model: Maintains baseline performance
- Trainable Policy Model: Optimized through training
- Prevents catastrophic forgetting
- Maintains model stability
- Enables controlled optimization
- Preserves general capabilities
2. Training Process
The training loop consists of:-
Generation Phase:
- Start with example prompts
- Generate multiple completions
- Use temperature sampling
- Create response variations
-
Evaluation Phase:
- Score completions with reward functions
- Calculate relative advantages
- Identify high/low performing outputs
-
Optimization Phase:
- Update policy model weights using the advantages calculated for each completion
- Maintain reference proximity by using the frozen reference model to generate completions
- Track performance metrics by monitoring the reward function scores and the total reward
3. Implementation Details
Key technical aspects:- Uses LoRA for efficient updates
- Leverages LoRAX (multi-LoRA) infrastructure
When to Use GRPO
Ideal Use Cases
Reasoning Tasks
- Complex problem solving
- Multi-step reasoning
- Strategic planning for agents
- Multi-agent coordination
- Logical analysis
- Natural language to code
Structured Outputs
- JSON generation
- Code completion
- Format adherence
- Schema validation
Optimization Goals
- Response quality
- Output consistency
- Task completion
- Error reduction
Implementing GRPO
1. Reward Function Design
Key principles for effective reward function design:- Clear Objectives: Define specific, unambiguous goals that align with your desired model behavior
- Measurable Outcomes: Create quantifiable metrics that can be consistently evaluated
- Comprehensive Coverage: Ensure the reward function captures all important aspects of the task
- Balanced Scoring: Weight different criteria appropriately to avoid overemphasizing any single aspect
- Robust Validation: Include error handling and edge cases to prevent reward manipulation
2. Training Configuration
Important parameters:- Number of training steps: Controls total iterations (typically 1000-5000)
- Number of generations per step: Controls the number of completions generated for each prompt (typically 8 or 16)
- Beta: Controls the balance between exploration and exploitation (0.1-1.0).
- Sampling parameters:
temperature: Higher values increase diversity, lower values increase consistencymax_tokens: Maximum length of generated responsestop_p: Nucleus sampling threshold (0.1-1.0) (fortemperature> 0)
3. Monitoring and Optimization
Key metrics to track:- Reward Function Trends: Monitor how individual reward functions evolve over time to identify learning patterns and potential issues
- Generation Diversity: Track the variety of responses being generated to ensure the model isn’t getting stuck in local optima
- Average Reward: Watch the mean reward across generations to gauge overall progress
- Reward Variance: Monitor the spread of rewards to understand model stability
- Convergence Rate: Track how quickly the model reaches stable performance
- Failure Modes: Document common types of incorrect or low-quality outputs by monitoring the logs and completions tabs.
- Fine-tune hyperparameters (e.g.
beta,temperature,max_tokens) - Monitor convergence (e.g. reward function trends, total reward)
Best Practices
1. Reward Function Design
- Start Simple: Begin with basic reward functions and incrementally add complexity as needed
- Comprehensive Testing: Test reward functions across diverse inputs and edge cases to ensure robust behavior
- Error Handling: Implement graceful error handling for unexpected inputs and edge cases
- Clear Documentation: Document all assumptions, requirements, and expected behaviors
- Graded Rewards: Use continuous scoring (0-1 range) instead of binary rewards to provide richer learning signals
- Multi-Objective Rewards: Combine format, correctness, and other relevant metrics for comprehensive feedback
- Validation: Include validation checks to ensure reward functions produce expected outputs
- Modularity: Design reward functions to be modular (one reward function per objective)
2. Training Process
- Start Small: Begin with a small number of training steps and gradually increase as needed
- Monitor Closely: Keep a close eye on reward function trends, generation diversity, and average reward to identify potential issues
- Wait For 40-50 Steps: Expect 40-50 steps before clear improvements
- Validate Frequently: Regularly validate reward functions to ensure they are working as expected
- Watch for Reward Hacking: Monitor for reward hacking by checking the logs and completions tabs
3. Reward Function Tips
Data Types in Example Dictionary
Theexample dictionary passed to reward functions contains string values for
all columns. Convert them as needed:
- Lists/dictionaries: Use
ast.literal_eval() - Numbers: Use
float()orint() - Booleans: Use
bool()
Partial Credit Scoring
Adding partial credit for partially correct responses helps models learn more effectively by providing directional feedback on how close the model is to the correct solution:- Binary rewards (0 or 1) provide limited learning signal
- Partial credit creates smoother learning gradients
- Example: 0.5 points for correct approach but wrong final answer
- Helps identify incremental improvements
External Libraries
You can use external packages for more sophisticated reward functions:- LLM-as-judge using OpenAI client
- NLP libraries like spaCy
- Scientific computing with NumPy
- External APIs for validation
runtime section of the RewardFunctionsConfig
object.
4. Monitoring and Debugging
Understanding Reward Graphs
Key metrics to monitor:total_reward: Average reward across all reward functions, indicating overall model performancetotal_reward_std: Standard deviation of rewards, measuring performance stability and consistency- Individual reward function trends: Track progress of each reward component separately
- Version-specific performance: Compare metrics across different model versions
- Steady upward trends in reward scores, showing continuous improvement
- Decreasing variance in rewards over time, indicating more stable performance
- Format rewards improving before task rewards, suggesting proper learning progression
- Consistent progress across model versions, demonstrating reliable training
Using Reward Logs
The Reward Logs tab helps:- Monitor training metrics and reward trends over time
- Debug reward function behavior using detailed logging and print statements
- Track and troubleshoot API response times and error rates
- Analyze periods of stagnant reward scores to identify potential issues
Analyzing Completions
The Completions tab provides powerful analysis capabilities:- Side-by-side comparison of model outputs across training iterations
- Detailed reward score breakdowns for each completion
- Visual progress tracking of model improvements over time
- Detection of potential reward hacking attempts
Common Challenges
-
Training Issues:
- Unstable or flat rewards: Monitor reward trends and adjust learning rate
- Slow convergence: Consider increasing batch size or simplifying reward criteria
- Quality regression: Check for reward hacking and adjust reward function weights
- Reward hacking: Implement reward shaping and validation checks
-
Implementation Problems:
- Complex reward calculations: Break down into smaller, testable components
- Integration issues: Use proper error handling and logging
- API timeouts: Implement retry logic and fallback mechanisms
-
Reward Function Issues:
- Non-numeric returns: Ensure all reward functions return float values
- Inconsistent scoring: Standardize scoring ranges and normalize outputs
- Missing error handling: Add try-catch blocks and default values
- Slow computation: Optimize calculations and cache results when possible
Frequently Asked Questions
How many training steps should I use?
We recommend starting with at least 200 steps. Most models show clear improvements after 40-50 steps, but the optimal number depends on:- Dataset size and complexity
- Number of reward functions
- Base model size
- Task difficulty
What if my rewards are not improving?
If rewards aren’t improving after 50 or 100 steps:- Check reward function implementation
- Verify training data quality
- Consider simplifying reward criteria
Can I use external APIs in reward functions?
Yes! Here are some common considerations to keep in mind:-
API costs and rate limits (e.g., OpenAI, Anthropic, etc.):
- Monitor usage to stay within your budget
-
Robust error handling
- Implement exponential backoff for retries
- Add comprehensive logging for debugging
- Handle various failure modes gracefully
-
Fallback mechanisms
- Maintain local alternatives for critical functions
- Define sensible default scores for failures
What’s the recommended reward range?
We recommend using scores between 0 and 1:- 0: Completely incorrect
- 0.1-0.9: Partial credit
- 1.0: Perfect response
- Provide clear learning signals
- Enable reward combination
Can I update reward functions during training?
Yes, you can modify reward functions while training:- Get current config using
pb.adapters.get_config() - Update the reward function
- Apply changes with
pb.adapters.update_config()
What if my model is “reward hacking”?
If the model finds unintended ways to maximize rewards (reward hacking):- Add validation checks for input/output quality
- Implement penalties for suspicious patterns
- Update reward functions to discourage exploitation
- Use multiple reward criteria to prevent single-metric optimization
- Review edge cases and boundary conditions
- Use partial credit scoring for better learning signals
Do the rewards need to be binary?
No! You can write more intricate reward functions that return a score between 0 and 1 (such as for similarity scores or partial credit scoring). You can take a look at section 4.1 of our blog post here for an example. In fact, adding partial credit for partially correct responses can help models learn tasks more effectively. While binary rewards (0 or 1) are simpler to implement initially, they provide limited signal for the model to learn from. If you notice your model is learning slowly with binary rewards, consider updating your reward functions to incorporate partial credit. This gives the model directional feedback on how close it is to the correct solution, creating a smoother learning gradient. For example, in a math problem, you might give 0.5 points for getting the approach right even if the final answer is wrong, or in a code generation task, award points for correct syntax even if the algorithm is not optimal.What if I need to use an external library in my reward function?
You can import any libraries in your reward function. However, please note that the import must be inside the function definition. If external packages need to be installed for your reward functions to work, you can specify them as follows:How do I pass additional columns to my reward functions?
You can add additional columns to your dataset beyond theprompt column. These
columns will be passed to your reward functions in the example argument as a
dictionary with the key being the column name and the value being the column
value.
Please note that all values in the example dictionary are strings, so
you will need to convert them to the appropriate type depending on your use
case. See more about data types in the next section.
What data types are supported in the example dictionary?
Theexample dictionary passed to reward functions contains string values for
all columns, regardless of their original data type. This means you’ll need to
convert non-string data types back to their original form. For example:
- Lists, dictionaries, sets and other data structures can be converted using
ast.literal_eval() - Numbers can be converted using
float()orint() - Booleans can be converted using
bool()
How do I interpret my reward graphs?
TheReward Graphs tab shows several charts that help you monitor the training
progress:
- total_reward: Shows the average total reward across all reward functions combined. An upward trend indicates the model is learning to optimize for the defined rewards.
- total_reward_std: Shows the standard deviation of the total reward, indicating how consistent the model’s performance is across different examples. Over time, this should decrease as the model more consistently gets higher rewards for its completions.
- Individual reward function graphs: Each reward function you define has a
graph showing how well the model is learning that specific objective. For
example, you might see separate graphs for
format_reward_func,correctness_reward_func, etc. The value graphed is the average reward for that function across all completions at the given training step.
- Look for an overall upward trend (except for the standard deviation graph, which should trend downwards). Progress may not be linear.
- It’s normal to need 40-50 training steps before seeing clear signs of improvement.
- Format-related rewards (like proper JSON structure) often improve first, before more complex task-specific rewards.
- High variance (spiky graphs) is common early in training but should generally decrease over time.
- If a specific reward function’s graph remains flat or decreases, you may need
to adjust its implementation by updating the reward function. It’s a good idea
to check the
Reward Logstab first to see if there is an obvious issue with it before working towards improving it.
How do I use the reward logs tab?
TheReward Logs tab displays any print statements from your reward functions
during training. This is a valuable debugging and monitoring tool that helps
you:
- Track training progress by showing which reward functions are executing, along with step and epoch numbers.
- Print out the reward score assigned to the completion before returning the reward score itself.
- Debug issues in your reward function implementations by inspecting the logged output.
- Monitor performance issues like API timeouts or errors.
- Investigate why reward scores might be flatlining or behaving unexpectedly.
How do I use the completions tab?
TheCompletions tab provides a detailed view into what your model is actually
generating during training. Here’s how to use it:
-
Select a Prompt: Use the prompt selection table to choose any prompt from
your training set. The table displays:
- Prompt Index: A unique identifier for each prompt.
- Prompt Text: The actual text of the prompt shown to the model.
- Prompt Length: Number of tokens in the prompt.
- Additional Columns: Any extra metadata or context provided with the prompt.
- Epoch: The training epochs where this prompt was used.
- Total Completions: Number of completions generated for this prompt.
-
Compare Completions: This section allows you to compare two completions
side-by-side.
- By default the right column shows the best completion generated at the most recent epoch. The left column allows you to select any other completion from the same prompt (from any epoch).
- A slider allows you to pick the epoch for the left column, and arrows allow you to switch between completions at that epoch.
- Each column displays the completion text and all individual reward scores (and the total reward).
- You can also easily compare any two completions (not just against the best one from the current epoch).
-
View all completions: Shows information about every completion generated
for the selected prompt.
- Epoch: The training epoch when the completion was generated.
- Completion: The full text output from the model.
- Individual reward scores: Separate columns for each reward function (e.g. format_reward_func_v1).
- Total: The combined reward score across all functions.
- Length: Number of tokens in the completion.
- View: Allows you to display this completion in the “Compare Completions” section.
Completions tab is particularly valuable for:
- Verifying that higher reward scores correspond to better quality outputs.
- Detecting reward hacking (where the model games the reward functions).
- Understanding how responses evolve throughout training.
- Identifying areas needing improved reward functions.
- Detecting breakthrough moments in the training process.
- Validating proper output formatting and structure.
How do I control the length of my GRPO training run?
By default, GRPO training runs for 1000 steps. You can modify this setting using thetrain_steps parameter in the GRPOConfig. In most cases, we do not
recommend lowering this value below 500 - GRPO runs take some time to converge.
Any additional tips?
It is usually good to have a format reward function so the model learns to respond in the format you want and a correctness reward function at the very least to see if the answer/expected output is good.Next Steps
- Explore Use Cases
- Learn about Production Deployment
- Reinforcement learning documentation